









Contents
- 1 Introduction: Why Your Choice in retrieval-augmented generation vs fine-tuning Matters
- 2 What is Retrieval-Augmented Generation (RAG)? The “Open-Book” Exam
- 3 What is Fine-Tuning? The Specialist’s Deep Training
- 4 Key Trade-Offs in retrieval-augmented generation vs fine-tuning
- 5 When to Choose retrieval-augmented generation vs fine-tuning: Actionable Insights
- 6 Real-World Scenarios: retrieval-augmented generation vs fine-tuning in Action
- 7 Conclusion: Strategizing Your AI Future
Introduction: Why Your Choice in retrieval-augmented generation vs fine-tuning Matters
As artificial intelligence becomes a core part of business operations, a critical question emerges: how do you tailor a powerful, general-purpose large language model (LLM) to your company’s specific needs? Your choice often boils down to two leading frameworks: Retrieval-Augmented Generation (RAG) and Fine-Tuning .
This decision is far from just a technicality; it’s a strategic business choice that impacts cost, efficiency, and the very capabilities of your AI system. Getting it right can lead to a powerful tool that drives value, while getting it wrong can mean wasted resources and an underperforming application .
This guide will break down the complexities of RAG and fine-tuning into clear, actionable insights, helping you choose the right strategy for your AI project.
What is Retrieval-Augmented Generation (RAG)? The “Open-Book” Exam
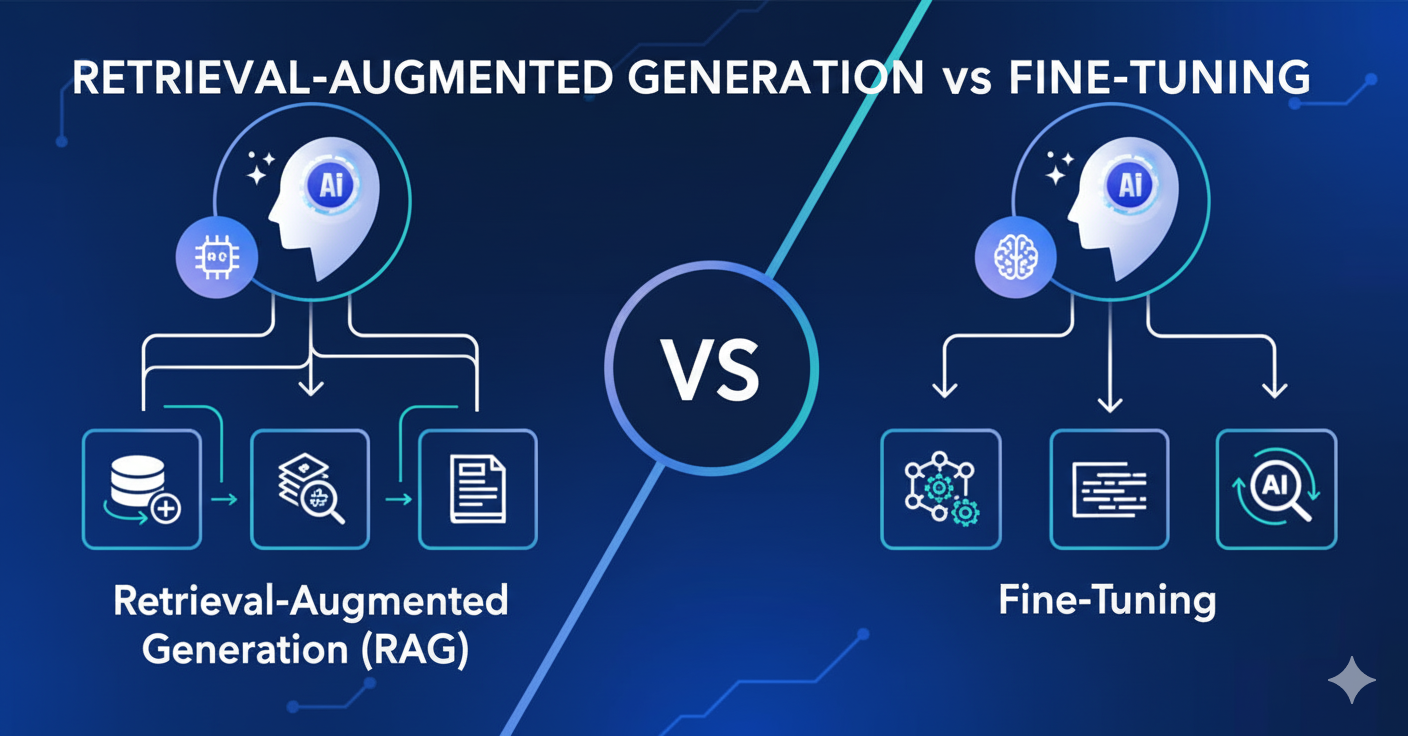
Introduced by Meta researchers in 2020, Retrieval-Augmented Generation (RAG) is an architecture that connects an LLM to an external knowledge base, such as a database of company documents or recent market data . Think of it as giving your AI model access to a specialized, constantly updated reference library at the moment a question is asked. The model itself remains unchanged; instead, it’s augmented with relevant, real-time information to ground its responses in facts .
How RAG Works
The RAG process follows a clear, multi-step pipeline:
- Query: A user submits a question.
- Retrieval: The system searches a connected knowledge base (like a vector database) for information relevant to the query .
- Augmentation: The retrieved information is combined with the user’s original query to create a super-charged, context-rich prompt .
- Generation: The LLM generates a response based on this augmented prompt, leading to an answer that is informed by both its internal knowledge and the provided, up-to-date context .
What is Fine-Tuning? The Specialist’s Deep Training
Fine-Tuning, in contrast, is the process of further training a pre-trained LLM on a smaller, specialized dataset to adjust its internal parameters (weights) for a specific domain or task . If RAG is an open-book exam, fine-tuning is like sending a general practitioner to medical school to become a specialized surgeon. The model fundamentally changes, internalizing new knowledge, styles, and terminologies directly into its architecture .
How Fine-Tuning Works
The fine-tuning process typically involves:
- Data Preparation: Collecting a high-quality dataset of labeled examples specific to your desired domain (e.g., customer service transcripts, legal contracts) .
- Model Training: The base model (e.g., GPT, Llama) undergoes additional training on this new dataset. Techniques like LoRA (Low-Rank Adaptation) have made this process more parameter-efficient and less computationally expensive .
- Evaluation and Deployment: The fine-tuned model is tested for performance gains and then deployed, now acting as a custom specialist .
Key Trade-Offs in retrieval-augmented generation vs fine-tuning
The core differences between these two approaches can be summarized across several key dimensions. Understanding these trade-offs is essential for making an informed decision.
| Feature | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Knowledge Freshness | Dynamic; can access real-time, up-to-date information | Static; frozen at the time of training, can become outdated |
| Implementation & Cost | Lower upfront cost, higher inference cost per query | High upfront computational cost for training, lower cost per query thereafter |
| Accuracy & Strengths | High factual accuracy with traceable sources; reduces “hallucinations” | High accuracy for specialized tasks, style, and domain language consistency |
| Flexibility & Maintenance | Easy to update; just modify the knowledge base without model retraining | Requires full retraining to incorporate new information, less flexible |
| Ideal Use Case | Dynamic domains needing current facts (e.g., news, customer support) | Stable domains needing specific tone/task performance (e.g., legal, medical) |
| Latency | Slightly slower due to the retrieval step | Faster inference as no external retrieval is needed |
When to Choose retrieval-augmented generation vs fine-tuning: Actionable Insights
The choice isn’t about which method is universally better, but which is better for your specific context. Here is a decision framework based on key project criteria.
Choose Retrieval-Augmented Generation (RAG) when:
- Your Knowledge Changes Frequently: RAG is superior for domains like financial markets, news aggregation, or cybersecurity, where information evolves daily . A RAG system can pull the latest Federal Reserve announcement or newly discovered software vulnerability to provide an accurate summary .
- Transparency and Traceability are Critical: In regulated industries like healthcare and law, the ability to cite sources is a major advantage. RAG allows users to verify an answer against the original document, building trust and aiding compliance .
- You Have Limited Training Resources or Data: RAG avoids the need for massive, labeled datasets and expensive GPU training cycles. You can get started by connecting your existing documentation, making it accessible for smaller teams .
Choose Fine-Tuning when:
- You Need a Specific Style, Tone, or Voice: If your application requires consistent brand voice, legal formalities, or a specific customer service style, fine-tuning can bake this directly into the model .
- Your Domain is Stable and Knowledge-Dense: For tasks involving deep, static expertise—such as analyzing legal contracts, medical coding, or technical troubleshooting—fine-tuning creates a powerful domain expert .
- Low Latency is a Priority: For real-time applications where every millisecond counts, a fine-tuned model’s ability to generate responses without a retrieval step provides a performance advantage .
The Winning Combo: Hybrid Approaches
You don’t always have to choose. Many enterprises are finding success with hybrid models that combine the strengths of both approaches .
A common strategy is to fine-tune a base model for core domain expertise and stylistic consistency, then layer RAG on top to inject real-time, specific knowledge . For example, a financial tech company could fine-tune a model on financial terminology and reporting styles, while using RAG to pull in a client’s latest portfolio data or the day’s market news to generate personalized advice .
Real-World Scenarios: retrieval-augmented generation vs fine-tuning in Action
- Healthcare: A RAG-powered medical assistant can retrieve the latest clinical study results or drug interaction information from updated databases to support doctors . A fine-tuned model, however, might be better suited for analyzing patient notes to suggest diagnoses based on learned patterns from historical data .
- Customer Support: A RAG chatbot can answer questions about new products and policies by fetching data from the latest manuals and FAQs . A fine-tuned chatbot can be trained on past support conversations to perfectly emulate your company’s desired tone and resolution style for common issues .
- Legal Sector: A RAG system is ideal for a lawyer needing to find precedents for a recent court ruling by searching through a vast, evolving database of case law . Fine-tuning is excellent for a model that needs to draft standard legal contracts using precise, pre-approved language and clauses .
Conclusion: Strategizing Your AI Future
The journey to customizing your large language model is defined by a clear strategic fork: Retrieval-Augmented Generation (RAG) for dynamic, transparent, and flexible knowledge integration, or Fine-Tuning for deep, stable, and efficient domain specialization.
There is no one-size-fits-all answer. By carefully evaluating your project’s requirements for knowledge freshness, available resources, and desired output, you can confidently select the path that aligns with your business goals. Remember, the most powerful and adaptable AI strategies often lie in the synergistic combination of both.
Sources and References
- RAG Vs. Fine Tuning: Which One Should You Choose?
- Fine-Tuning vs RAG in 2025: Which Approach Wins
- Understanding Fine – Tuning vs RAG : Whats best? | APIpie
- LLM Fine-Tuning vs Retrieval-Augmented Generation (RAG)
- RAG vs Fine Tuning: How to Choose the Right Method
- RAG – Fine : Which Is Better for Improving AI… – Designveloper tuning
- RAG vs Fine Tuning: The Hidden Trade-offs No One Talks …
- Retrieval-Augmented Generation vs Fine-Tuning: Which to …
- Fine-Tuning vs RAG: Key Differences Explained (2025 …
- LLM fine ‑ tuning vs. RAG vs. agents: a practical… – MITRIX Technology



