Contents
Introduction
The rapid evolution of large language models (LLMs) and AI-driven applications has ignited a vital debate among practitioners and enterprises alike: which approach best balances cost, performance, and scalability Retrieval-Augmented Generation (RAG) or traditional Fine-Tuning? As AI integrations become more critical to production systems, understanding the nuances of these LLM training methods is essential for efficiency and maximizing value.
This article dives deep into the strengths and limitations of RAG vs fine tuning, with particular focus on their operational costs, effectiveness in real-world scenarios, and ability to scale seamlessly. By the end, you’ll have a clear framework to decide which approach aligns best with your AI data retrieval needs and project goals.
Understanding RAG and Fine-Tuning: A Primer
What is Retrieval-Augmented Generation (RAG)?
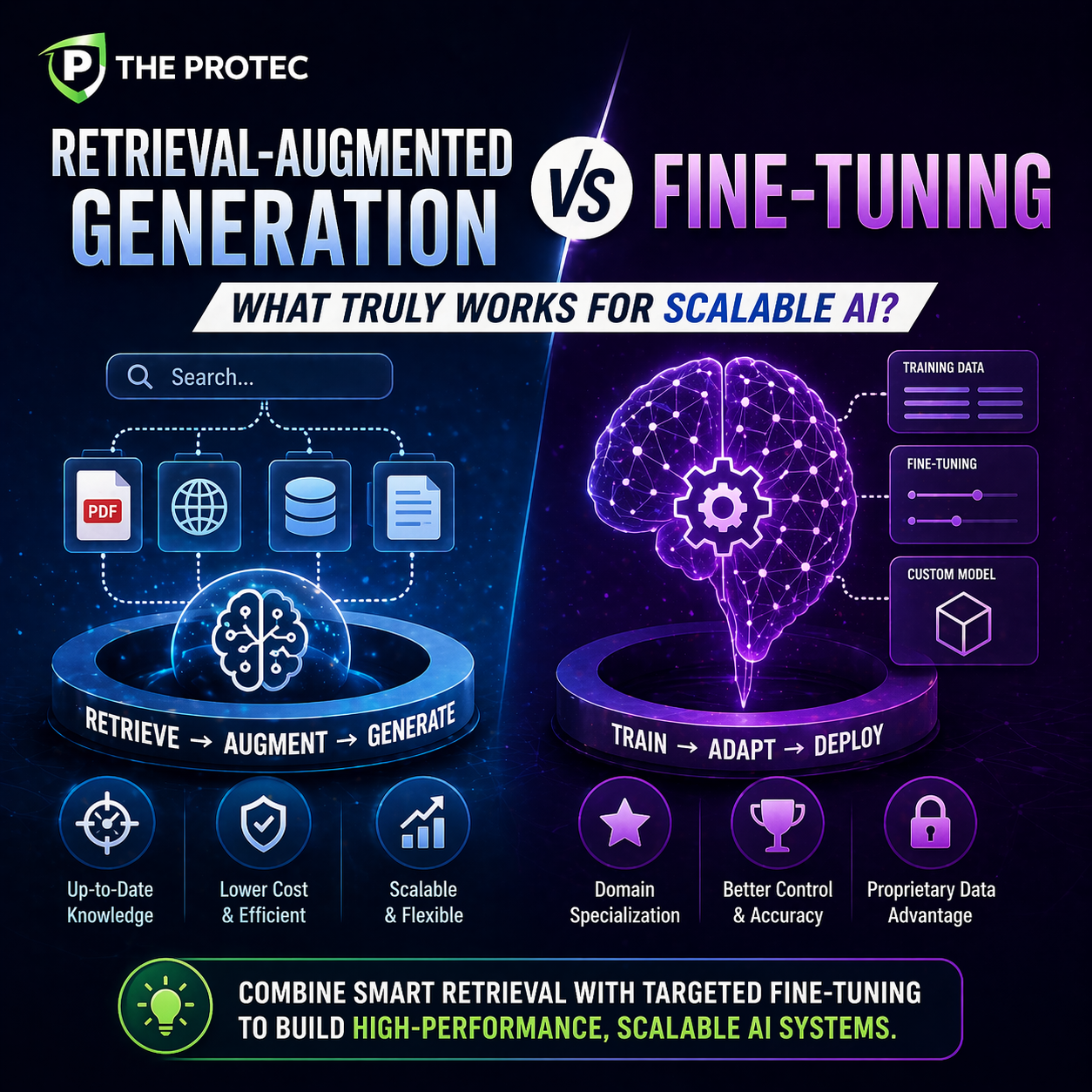
Retrieval-Augmented Generation is a technique where a pretrained language model is combined with an external knowledge base or database. When a query is received, the system first retrieves relevant documents or data snippets using information retrieval methods, then feeds them as context to the generator (usually a pretrained LLM like GPT or T5) to produce informed, up-to-date responses.
This hybrid approach effectively bridges the gap between static pretrained knowledge and dynamic or domain-specific information, ensuring outputs are accurate and grounded in current data.
What is Fine-Tuning?
Fine-tuning involves updating the weights of a pretrained LLM by training it on domain-specific datasets or tasks. This specialized training adjusts the model to perform better on specific kinds of prompts or contexts by internalizing knowledge rather than relying on external retrieval.
In fine-tuning, the model evolves from a generic language understanding system to a niche expert within a particular domain or use case, allowing for highly tailored and often more fluent outputs.
Performance Comparison
Response Relevance and Contextual Accuracy
- RAG: Excels at incorporating real-time or rapidly changing data due to direct retrieval. This ensures answers reflect the latest available knowledge, avoiding hallucination or outdated information common in static LLMs.
- Fine-Tuning: Produces fluent and contextually consistent responses within the fine-tuned domain. However, it can struggle with memorizing vast or dynamic datasets unless continuously retrained.
Handling Domain-Specific Knowledge
Fine-tuning allows the model to internalize nuanced domain knowledge that may be subtle or complex, sometimes outperforming retrieval-augmented solutions if data is well-curated and training resources are sufficient.
Conversely, RAG systems require domain-appropriate retrieval indexes and effective retrieval models, which can be challenging to engineer but offer flexibility as domains evolve.
Latency and User Experience
- RAG: Introduces overhead from querying external databases or search indexes, which can impact latency depending on the retrieval system’s efficiency.
- Fine-Tuning: Generally faster at inference time since everything is embedded within the model itself, but potential performance drops if the fine-tuned model is large.
Cost Analysis
Upfront and Operational Costs
- Fine-Tuning: Requires significant computational resources upfront, especially for large LLMs. Training can be expensive, necessitating specialized hardware and expertise.
- RAG: Costs focus on maintaining a retrieval infrastructure (search indexes, databases) and hosting the pretrained model. Typically lower upfront costs but may incur operational expenses related to data storage and retrieval scaling.
Maintenance and Data Updates
Fine-tuning models require retraining or continuous fine-tuning to remain current with evolving data, which is time-consuming and costly.
RAG’s modular architecture allows for independent updates of the knowledge base without retraining the large generative model, greatly reducing ongoing expenses and effort.
Scalability Considerations
Data Volume and Diversity
The ability to handle large, heterogeneous datasets is critical in production AI. RAG inherently supports scaling knowledge repositories and adding new content swiftly by simply updating or expanding the retrieval database. Fine-tuning, in contrast, encounters diminishing returns and increased costs as dataset size and complexity grows, often requiring full retraining cycles.
Model Adaptability
- RAG: Seamlessly adapts to changing knowledge landscapes without major interruptions, making it ideal for environments with rapidly evolving content such as news, medical research, or dynamic FAQs.
- Fine-Tuning: Less flexible once deployed, as model weights are fixed unless further training is done. Continuous domain shifts necessitate frequent retraining, complicating scalability.
Use Cases That Favor RAG or Fine-Tuning
When to Prefer Retrieval-Augmented Generation
- Applications requiring up-to-the-minute information like financial data or news summarization.
- Systems that must integrate extensive and variable documentation, such as enterprise knowledge bases.
- Projects with tight budgets needing fast deployment and minimal retraining overhead.
When Fine-Tuning Shines
- Specialized tasks where domain expertise is subtle and embedded linguistic patterns outweigh the need for external data.
- High-volume, latency-sensitive applications where querying external databases could cause bottlenecks.
- Systems targeting narrow verticals such as legal document analysis or specialized medical diagnostics where quality responses come from deep model knowledge.
Practical Recommendations for Production Systems
Combining both approaches can yield the best outcomes; using fine-tuned models enhanced with retrieval augmentation offers robustness, relevance, and flexibility.
Enterprises should carefully assess their data dynamics, user expectations, available budgets, and latency requirements before committing to either strategy. Investing in a hybrid system architecture with modular retrieval and fine-tuning components is increasingly becoming a best practice.
FAQs
Is Retrieval-Augmented Generation better than fine-tuning for all AI projects?
Not necessarily. RAG provides advantages in cost and scalability for dynamic data, while fine-tuning can deliver higher accuracy and fluency for narrow, stable domains. The choice depends on project requirements and resource constraints.
How often do fine-tuned models need retraining to stay effective?
It varies by application, but typically fine-tuned models require retraining or updates whenever significant domain knowledge changes occur. This could be quarterly or even more frequently for fast-moving domains.
Can RAG handle unstructured data effectively?
Yes, RAG systems can incorporate unstructured data such as documents or web content by indexing it appropriately using advanced retrieval techniques like vector search, enabling the generation model to use relevant context efficiently.
Conclusion
As AI systems mature, efficient LLM training methods become crucial for sustainable, high-performing deployments. The debate of RAG vs fine tuning ultimately boils down to the tension between flexibility, cost, and speed.
Retrieval-Augmented Generation offers a scalable, cost-effective solution that thrives on real-time data integration, while fine-tuning delivers refined expertise at the expense of agility and expense. Evaluating your organization’s specific needs and data environment will guide you toward the ideal approach or combination thereof.
For further insights into AI data retrieval techniques, tools like Semantic Search AI provide excellent resources to understand the latest in information retrieval integration.