Contents
Introduction
Large Language Models (LLMs) have revolutionized AI-powered applications with capabilities that span natural language understanding, generation, and complex decision-making. However, deploying LLMs in production environments introduces significant challenges around reliability, accuracy, and user trust. This is where AI observability comes into play a critical practice that enables developers and operators to monitor, analyze, and debug LLM applications effectively.
In this guide, we delve deep into how AI observability helps tackle key issues such as hallucinations, latency fluctuations, and output quality degradation. We also explore the latest AI monitoring tools designed to provide real-time insights into the performance and behavior of LLM systems. Whether you’re maintaining a chatbot, content generator, or an AI assistant, understanding how to instrument and observe these models in production is pivotal to delivering reliable AI experiences.
Understanding AI Observability in LLMs
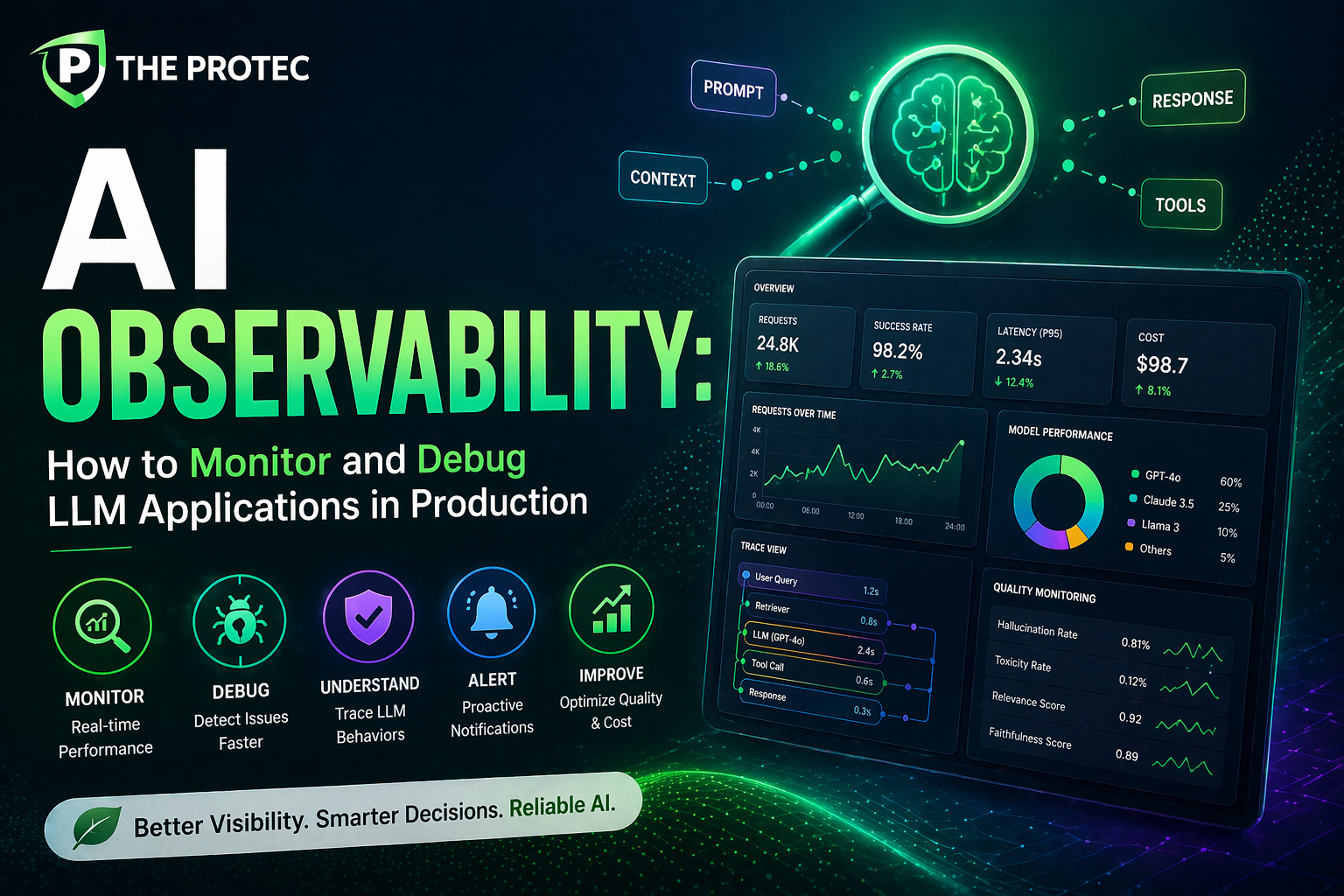
AI observability extends the concept of traditional software observability into the domain of machine learning, emphasizing continuous tracking of model-specific metrics and behaviors. Unlike conventional applications where code execution paths dominate monitoring strategies, LLMs generate probabilistic outputs influenced by vast training data and context. This complexity necessitates new monitoring strategies focused on model outputs, input distributions, and interaction patterns.
Core aspects of AI observability for LLM applications include:
- Output Integrity: Monitoring hallucinations (inaccurate or fabricated information) that degrade trust.
- Latency Tracking: Measuring response times across various user queries and loads to maintain performance SLAs.
- Quality Metrics: Evaluating relevance, coherence, and factual correctness of generated text.
- Input Stability: Detecting drift in input data or scenarios that can confuse the model.
- Error Correlation: Linking model errors back to specific inputs, prompts, or model configurations.
Observability enables informed troubleshooting and proactive model governance, a vital step beyond simple monitoring.
Tracking Hallucinations in Production LLMs
Hallucinations when LLMs generate plausible but false or misleading information pose a major challenge to deployment in real-world applications, especially those handling sensitive or critical tasks.
Identifying Hallucinations
Detection starts with establishing baseline expectations and definitions of hallucinations relevant to the domain. Techniques involve:
- Automated Fact-Checking: Integrating fact verification tools to cross-reference LLM outputs with trusted external knowledge bases or APIs.
- Semantic Similarity Scoring: Leveraging embeddings or semantic search to compare generated text against valid reference content.
- Human-in-the-Loop Review: Sampling outputs flagged by automatic systems for expert evaluation, refining detection models.
Mitigating Hallucinations
Once hallucinations are tracked, observability tools can help map them to specific conditions such as certain prompt types, model stages, or data input anomalies. Strategies include:
- Prompt Refinement: Adjust prompts in response to recurring error patterns.
- Model Ensemble: Combining outputs from multiple models to increase accuracy.
- Confidence Thresholding: Flagging or rejecting outputs below confidence or quality benchmarks.
Tracking and debugging hallucinations continuously ensures AI applications maintain trustworthiness over time.
Monitoring Latency and Performance
Latency remains a critical factor in user experience for LLM-powered apps. AI observability empowers teams to track fine-grained performance metrics and identify bottlenecks as usage scales.
Key Latency Metrics
- End-to-End Response Time: Time from user request to model output delivery.
- Token Generation Time: Duration taken to generate each token or response segment.
- Infrastructure Metrics: CPU/GPU utilization, memory consumption, and network latency affecting inference.
Debugging Latency Issues
Observability platforms that integrate system and application metrics help pinpoint whether lags arise from model size, inefficient prompting, hardware constraints, or network disruptions.
- Implementing caching or result reuse to optimize repeated queries.
- Optimizing model architectures or distilling larger models to smaller ones.
- Scaling infrastructure based on usage patterns, guided by real-time monitoring.
Evaluating Output Quality Beyond Hallucinations
Output quality encompasses attributes beyond factuality, such as relevance, coherence, fluency, and alignment with user intent. Observability in production ensures these aspects remain consistent.
Measuring Quality Metrics
- User Feedback Loops: Incorporating direct user ratings or implicit signals (clicks, corrections) to gauge satisfaction.
- Automated Scoring: Using NLP metrics like BLEU, ROUGE, or newer task-specific evaluators tailored to generation contexts.
- Drift Detection: Monitoring changes in input or output distributions that may signal model degradation over time.
Continuous Improvement
By correlating quality metrics with deployment events, training iterations, or infrastructure changes, teams identify interventions to enhance user experiences and accuracy.
Top AI Monitoring Tools for LLM Applications
Several sophisticated tools have emerged to meet the unique observability needs of LLMs:
- Langchain Insights – Provides detailed tracing and logging of prompt inputs, outputs, and chaining behaviors designed for generative AI workflows.
- Weave.ai – Offers real-time monitoring and error analysis tailored for LLM performance and output validation.
- OpenAI’s Plugin & Logging Frameworks – Enable integrated logging and context monitoring, especially in multimodal LLM deployments.
- Prometheus and Grafana – Traditional metrics gathering paired with custom exporters for deep LLM inference monitoring.
Choosing the right tool depends on architecture, model scale, and observability goals. Combining automated tooling with expert oversight often yields the best results.
Best Practices for Implementing AI Observability
- Instrument Early: Embed monitoring hooks during development, not only in production, to capture key signals from day one.
- Define Clear Metrics: Establish KPIs covering hallucination rate, latency percentiles, output quality, and error sources.
- Automate Alerts: Use anomaly detection to proactively notify teams on unexpected patterns or degradations.
- Maintain Data Privacy: Ensure user data and interactions logged for observability comply with privacy standards.
- Enable Explainability: Track model decisions and outputs in ways that foster accountability and transparency.
- Iterate and Adapt: Continuously refine observability frameworks as models evolve and use cases expand.
FAQ
What is AI observability and why is it critical for LLM applications?
AI observability is the practice of continuously monitoring AI models, especially LLMs, to gain insights into their outputs, performance, and behavior. It is critical because LLMs can produce inconsistent or erroneous results such as hallucinations, and observability helps detect, diagnose, and correct these issues to ensure reliability in production.
How can I detect hallucinations in LLM outputs effectively?
Effective hallucination detection involves a combination of automated fact-checking against trusted sources, semantic similarity analysis to spot deviations from expected content, and periodic human review to validate questionable outputs. Incorporating feedback loops improves detection accuracy over time.
Which key metrics should I monitor for AI observability in LLMs?
Focus on metrics like hallucination frequency, output confidence scores, latency (end-to-end and per token), throughput, resource utilization, user satisfaction signals, and data drift indicators. Together, these provide a holistic view of model health and user experience.
Conclusion
Deploying Large Language Models in production is an exciting yet challenging endeavor. AI observability is the cornerstone that empowers teams to maintain control over LLM applications, tracking and eliminating hallucinations, optimizing latency, and safeguarding output quality. By adopting targeted monitoring tools, defining robust metrics, and fostering continuous feedback, organizations can unlock the full potential of LLMs with confidence and transparency.
For further reading on AI monitoring best practices, visit O’Reilly’s guide on AI Observability.