Contents
- 1 Introduction
- 2 What is a Vector Database?
- 3 Why Vector Databases Matter for AI Applications
- 4 How Embeddings Search Powers Semantic Retrieval
- 5 Vector Databases in Retrieval-Augmented Generation Systems
- 6 Key Features of Modern AI Databases
- 7 Challenges and Future Directions
- 8 Real-World Examples of Vector Databases in Action
- 9 Frequently Asked Questions (FAQ)
- 10 Conclusion
Introduction
In the rapidly evolving landscape of artificial intelligence, managing and searching through complex data efficiently has become essential. Traditional databases, optimized for structured data and exact matches, fall short when handling the high-dimensional, unstructured data that modern AI applications demand. Enter vector databases: specialized systems designed to store and query vector embeddings that represent data in numerical form, enabling semantic understanding and retrieval at scale.
This article delves into the fundamentals of vector databases, how embeddings search powers advanced AI systems, and why these technologies are foundational to modern AI applications, including Retrieval-Augmented Generation (RAG) systems. By grasping these concepts, businesses and developers can unlock smarter, faster, and more context-aware AI solutions.
What is a Vector Database?
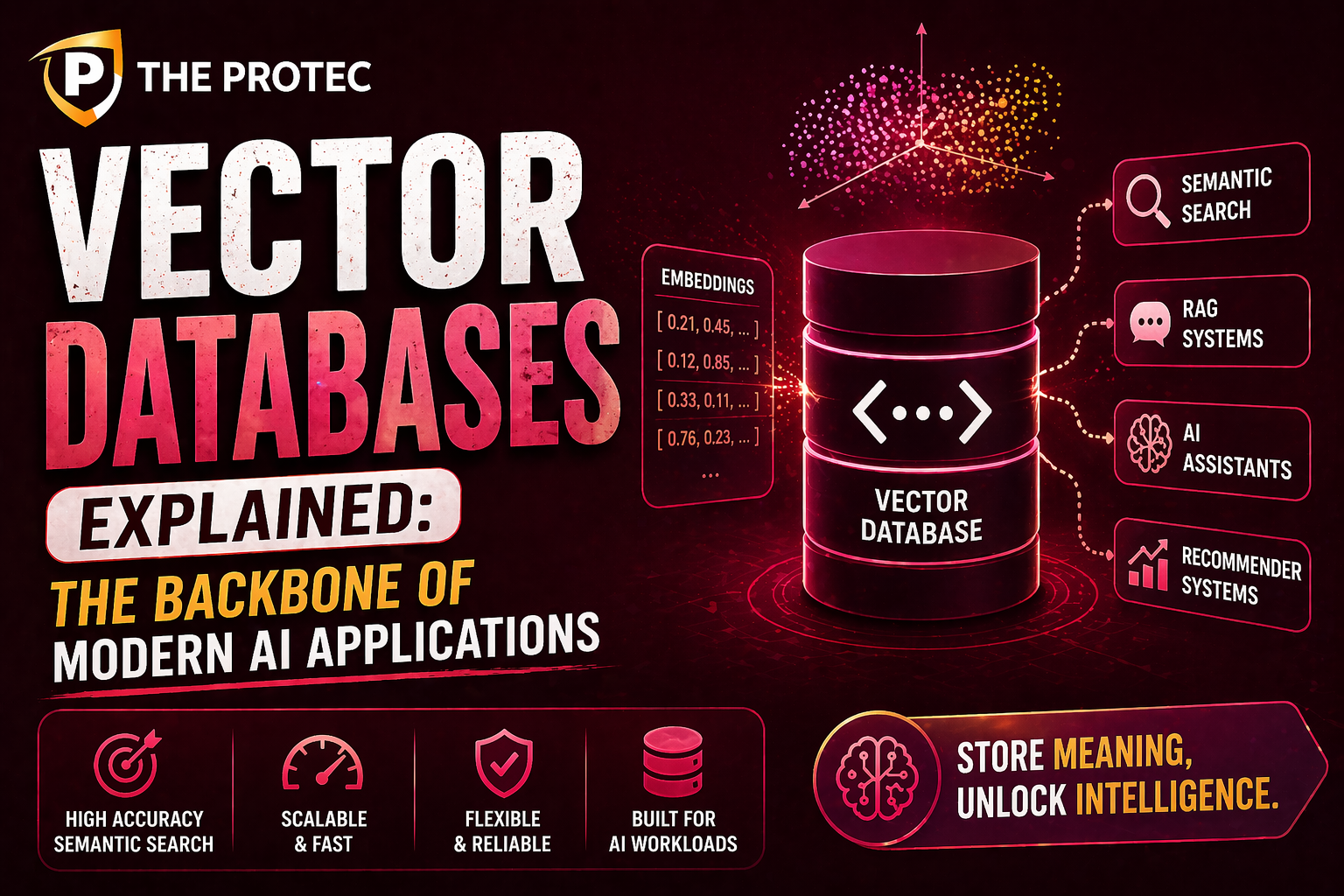
A vector database stores and manages data in the form of vectors numerical arrays encoding the semantic information of objects such as text documents, images, audio, or video. Unlike traditional relational databases optimized for exact value matching, vector databases are designed for similarity search, where the goal is to find vectors closest to a query vector in a high-dimensional space.
These vectors are typically generated through machine learning models, such as deep neural networks, that transform raw inputs into embeddings capturing contextual and semantic relationships. For example, a sentence embedding may capture the meaning of a phrase such that semantically similar sentences have embedding vectors clustered closely together.
Why Vector Databases Matter for AI Applications
Modern AI applications increasingly depend on understanding and processing unstructured data. These applications include natural language processing (NLP), computer vision, recommendation engines, and more. Vector databases play a critical role in enabling these AI systems to efficiently perform:
- Semantic Search: Going beyond keyword matching to find results that match the intent or meaning of a query.
- Content Recommendations: Matching user preferences based on similarity in embedding space.
- Retrieval-Augmented Generation (RAG): Combining external knowledge retrieval with large language models for accurate and context-aware content generation.
Without vector databases, these tasks would be computationally prohibitive or outright impossible at scale.
How Embeddings Search Powers Semantic Retrieval
At the core of vector databases lies embeddings search, the process of querying embedded vectors to find data points closest in meaning to a given query. Here’s why embeddings search is crucial:
1. Representing Meaning in High-Dimensional Space
Embeddings map raw data to a continuous vector space where semantic similarity corresponds to geometric proximity. For instance, words like “king” and “queen” will have vectors near each other, reflecting their conceptual relatedness. This property enables machines to reason about nuances in language or content.
2. Similarity Metrics and Efficient Search
Vector databases measure proximity using similarity metrics such as cosine similarity or Euclidean distance. Efficient search algorithms including Approximate Nearest Neighbor (ANN) methods like Hierarchical Navigable Small World (HNSW) graphs or product quantization enable rapid retrieval from billions of vectors.
3. Contextual and Multimodal Retrieval
Embeddings from modalities like text, images, and audio can coexist in vector databases, allowing advanced semantic retrieval across data types. For example, a query image can retrieve similar images or associated textual descriptions, bridging modalities and enriching the user experience.
Vector Databases in Retrieval-Augmented Generation Systems
Retrieval-Augmented Generation (RAG) is a breakthrough approach that enhances language models by integrating external knowledge retrieved in real-time from vector stores. Here’s how vector databases underpin RAG:
1. Background on RAG
Large language models (LLMs) excel at generating fluent text but are limited by fixed training data and can hallucinate facts. RAG combines LLMs with document retrieval to ground outputs in relevant, up-to-date information.
2. Semantic Search as a Retrieval Backbone
When a user poses a query, the system embeds it and searches the vector database to retrieve semantically relevant documents or passages. These retrieved pieces augment the input to the language model, guiding it toward factual and precise responses.
3. Benefits and Use Cases
- Improved Accuracy: Language generation is informed by specific knowledge sources rather than relying solely on generalized training.
- Dynamic Knowledge Updating: The vector database can be continuously updated with new data without retraining the LLM.
- Scalable Knowledge Retrieval: Vector databases efficiently handle massive corpora and find relevant content quickly.
Use cases range from customer support bots referencing product manuals, to scientific research assistants pulling up the latest studies during conversation.
Key Features of Modern AI Databases
While vector databases specialize in embeddings search, modern AI databases integrate additional capabilities to support evolving AI workloads:
- Hybrid Search: Combining vector similarity with traditional keyword filters to refine results.
- Scalability and Distributed Architectures: Handling billions of vectors across multiple nodes for horizontal scaling.
- Real-Time Updates: Supporting rapid ingestion and querying to maintain freshness of data.
- Multimodal Support: Storing and searching embeddings from different data types simultaneously.
- Integration with ML Pipelines: Seamlessly plugging into AI workflows and frameworks for embedding generation and inference.
Challenges and Future Directions
Despite their immense potential, vector databases face ongoing challenges:
- High Dimensionality: Searching efficiently in very high dimensions remains computationally intensive.
- Data Quality and Embedding Bias: Poorly trained embeddings can lead to inaccurate retrieval or biased outcomes.
- Standardization: Lack of unified standards and interoperability across vector database solutions.
- Privacy Concerns: Managing sensitive data within embeddings requires robust security.
Future advances will likely focus on improved algorithms for approximate nearest neighbor search, embedding explainability, and tighter integration between vector search and generative AI models.
Real-World Examples of Vector Databases in Action
Several organizations and platforms showcase the transformative impact of vector databases:
- Semantic Scholar: Uses vector search to enable researchers to find relevant scientific papers beyond keyword matching.
- E-commerce Personalization: Retailers deploying vector databases for product recommendations based on user intent and preferences.
- Conversational AI: Chatbots integrating RAG architectures to retrieve up-to-date information and enhance dialogue accuracy.
One can explore open-source options like Milvus or commercial platforms such as Pinecone and Weaviate to build scalable vector search solutions.
Frequently Asked Questions (FAQ)
What distinguishes a vector database from a traditional database?
Traditional databases focus on structured data and exact matches using indexes like B-trees. Vector databases, however, store high-dimensional vectors representing unstructured data and enable similarity-based search, which is essential for semantic understanding in AI applications.
How do vector databases generate and store embeddings?
Embeddings are generated by machine learning models that convert data like text, images, or audio into dense numerical vectors. These vectors are then indexed and stored within the vector database to facilitate fast similarity search and retrieval.
What makes embeddings search critical for retrieval-augmented generation?
Embeddings search allows RAG systems to retrieve relevant documents based on semantic similarity rather than keyword overlap. This enables language models to ground their generated responses in accurate, contextually relevant information, improving the quality and reliability of AI-generated content.
Conclusion
Vector databases represent a fundamental shift in how data is stored, searched, and utilized in AI. By enabling efficient embeddings search, they power semantic retrieval and retrieval-augmented generation, which are critical to next-generation AI applications that require contextual understanding and real-time knowledge access.
As AI continues to advance, the role of vector databases will only deepen, fostering smarter applications capable of bridging the gap between vast amounts of unstructured data and human-like comprehension. Embracing these technologies today prepares businesses and developers for the intelligent solutions of tomorrow.